
数据库系统研究的是:如何用计算机有效地组织和管理数据
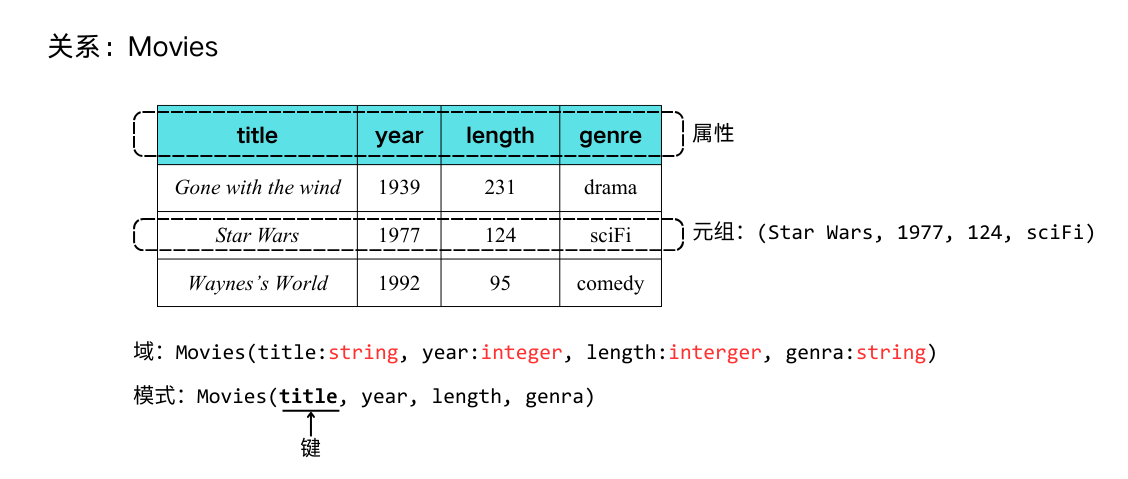
关系数据模型
数据库与DBMS
| 概念 | |
|---|---|
| 数据(Data) | 数据库存储的基本对象,数字、文本、图形、音频、视频等均可看作数据 |
| 语义 | 数据的标签,具备语义的数据才可成为信息 |
| 数据库(Database) | 长期存储在计算机内的、有组织的、可共享的数据的集合 |
| 数据库管理系统(DBMS) | 位于用户与操作系统之间的一层数据管理软件,通过调用系统资源操作和管理数据 |
关系数据模型
| 概念 | |
|---|---|
| 关系数据模型 | 用于描述数据的符号语言,它包括结构、操作和约束等3个部分。 |
| 关系(Relation) | 二维的表格 |
| 属性(Attribute) | 关系列的表头,描述了该列内容的实际含义 |
| 模式(Scheme) | 关系与其属性的范式 |
| 元组(Tuples) | 关系的具体内容 |
| 域(Domains) | 关系的数据类型 |
| 键(Key) | 关系的其中一个元素 |
关系数据库语言
关系代数用于在关系数据模型上查询和修改数据,它的输入和输出均为关系,因此可视为一个封闭的代数系统。
SQL语句的核心就是关系代数。
SQL的功能远低于C语言和Java,为什么使用它?
- 关系代数的用途十分广泛。
- SQL的编译十分便捷,易于优化。
关系代数(RA)
代数(Algebra)是操作数(Operands)和运算符(Operators)的集合。
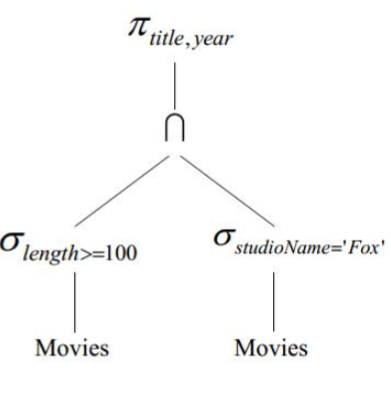
通过关系代数的运算符和各种关系相连接。可以得到关系表达式。例如:
$$ R(t,y,l,i,s,p) := \sigma_{\mathrm{length} \leqslant 100}(\mathrm{Movies}) $$$$ S(t,y,l,i,s,p) := \sigma_{\mathrm{studioName='Fox'}}(\mathrm{Movies}) $$
$$ Answer(title, year) := \pi_{t,y}(R \cap S) $$
事实上,所有表达式都可以写成树 的形式。上式即可表达为:
集合运算
| 集合操作 | 符号 | 作用 |
|---|---|---|
| 并(Union) | $R \cup S$ | 关系 $R$ 和 $S$ 中所有的内容,相同的只出现一次 |
| 交(Intersection) | $R \cap S$ | 关系 $R$ 和 $S$ 中共同存在的内容 |
| 差(Difference) | $R - S$ | 关系 $R$ 中存在但不在关系 $S$ 中 |
对应的SQL语言:
1(SELECT * FROM R) UNION (SELECT * FROM S); --- 并
2(SELECT * FROM R) INTERSECT (SELECT * FROM S); --- 交
3(SELECT * FROM R) EXCEPT (SELECT * FROM S); --- 差
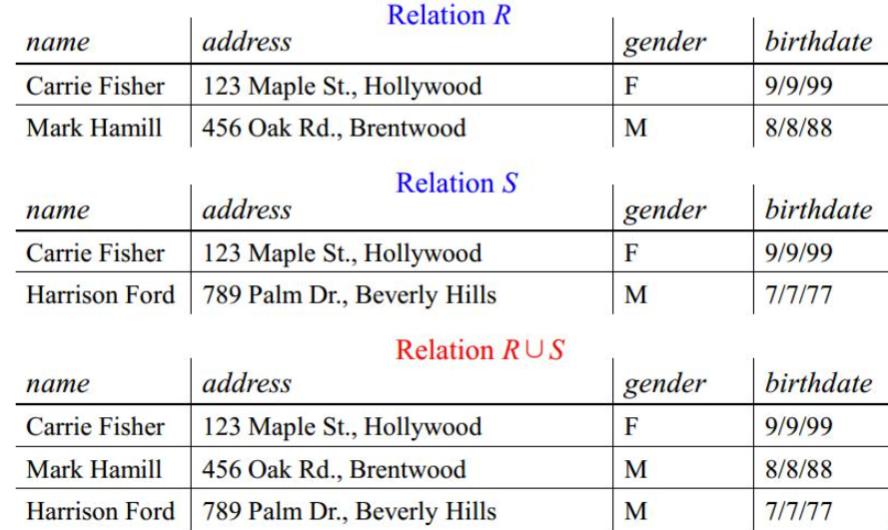
集合运算中的关系 $R$ 和 $S$ 的属性必须相同且排列顺序一致,且每个属性在两者中的域(数据类型)必须相同。
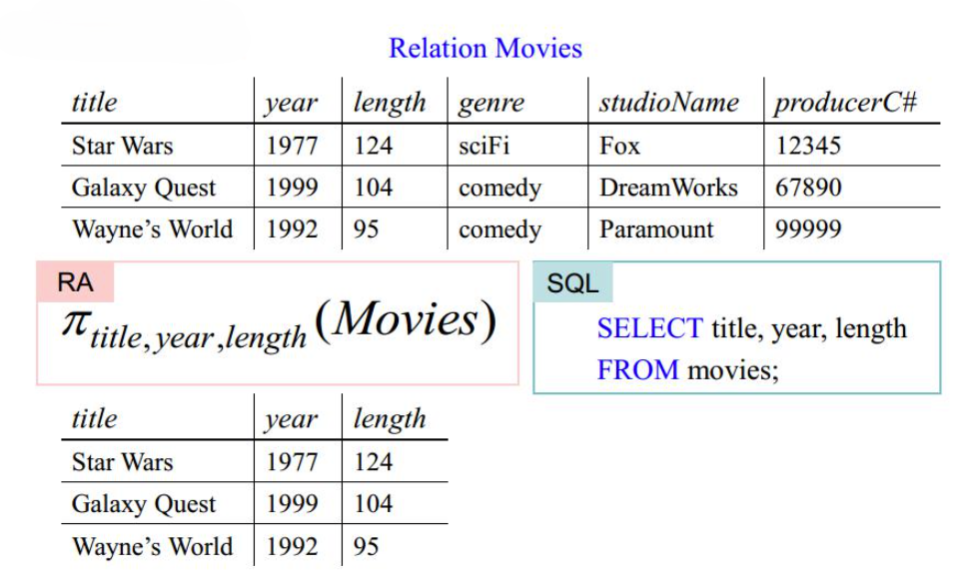
投影运算
从关系 $R$ 生成一个仅包含 $R$ 部分属性的新关系(Project),可表示为 $\pi_{A_1, A_2, \cdots, A_n}(R)$
对应的SQL语言:
1SELECT A1, A2, ..., An FROM R;
选择运算
生成关系 $R$ 满足条件 $C$ 的元组子集作为一个新关系,结果关系的模式与原关系的相同(SELECTION)。可表示为:$\sigma_{C}(R)$
用集合表示则可写作:$\sigma_{C}(R) = \{ t | t \in R \land C(t) = \mathrm{true} \}$
对应的SQL语言:
1SELECT * FROM R WHERE C;
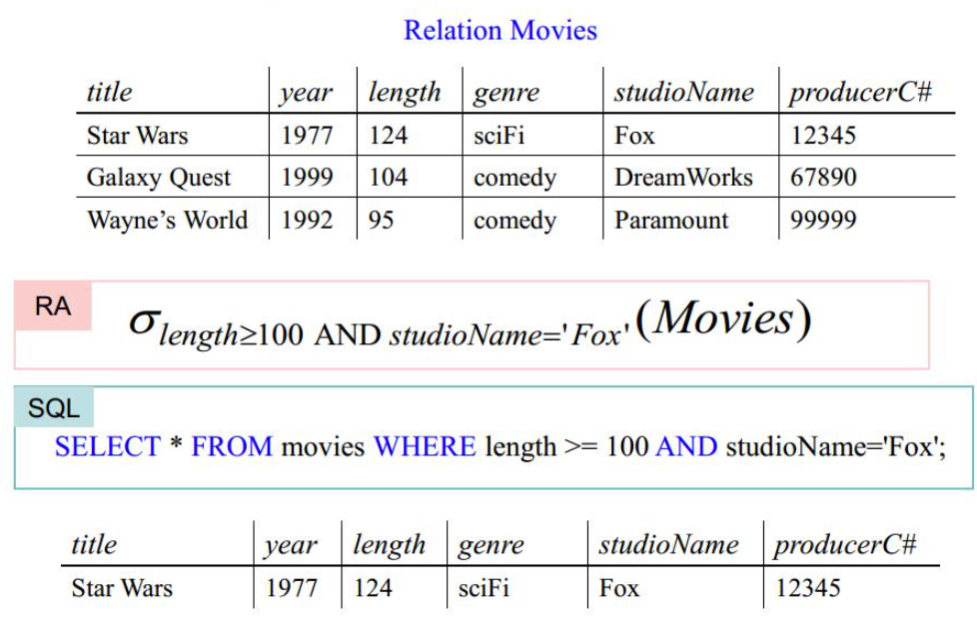
笛卡尔积
选择关系 $R$ 的一个元素为有序对的第一个元素,关系 $S$ 的一个元素为第二个元素,以此类推形成的新关系(Cartesian Product)。可表示为:$R \times S$
对应的SQL语言:
1SELECT * FROM R CROSS JOIN S;
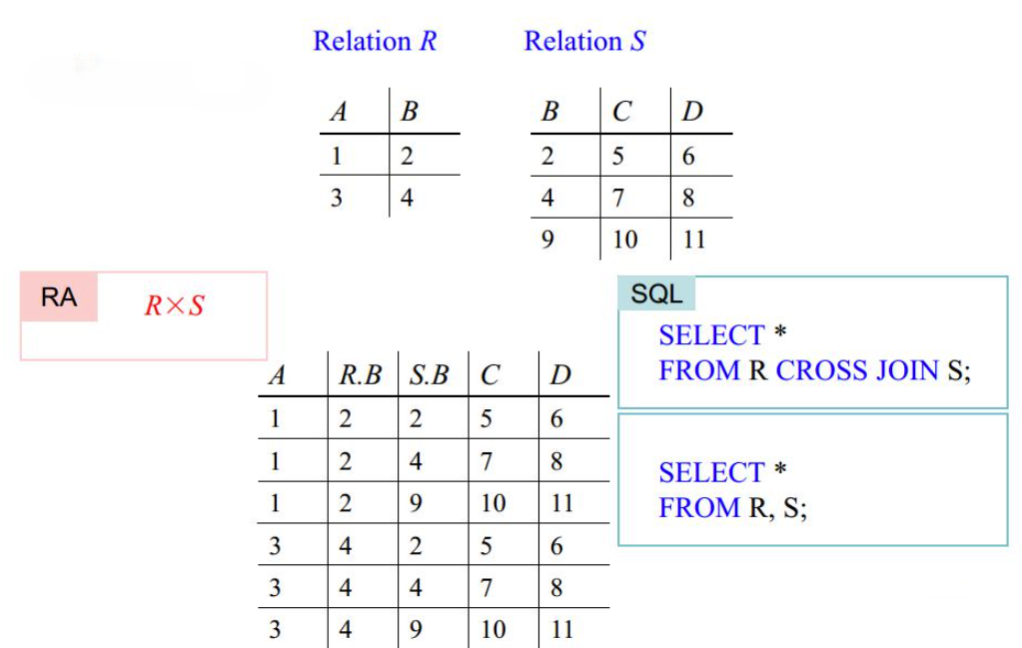
自然连接
设 $A_1, A_2, \cdots, A_n$ 为关系 $R$ 和 $S$ 中所有共同属性,当两者的共同属性的内容完全一致时则合并为一个关系,合并的结果应包含关系 $R$ 和 $S$ 中的所有属性(Natural Joins)。可表示为:$R \bowtie S$
对应的SQL语言:
1SELECT * FROM R NATURAL JOIN S;
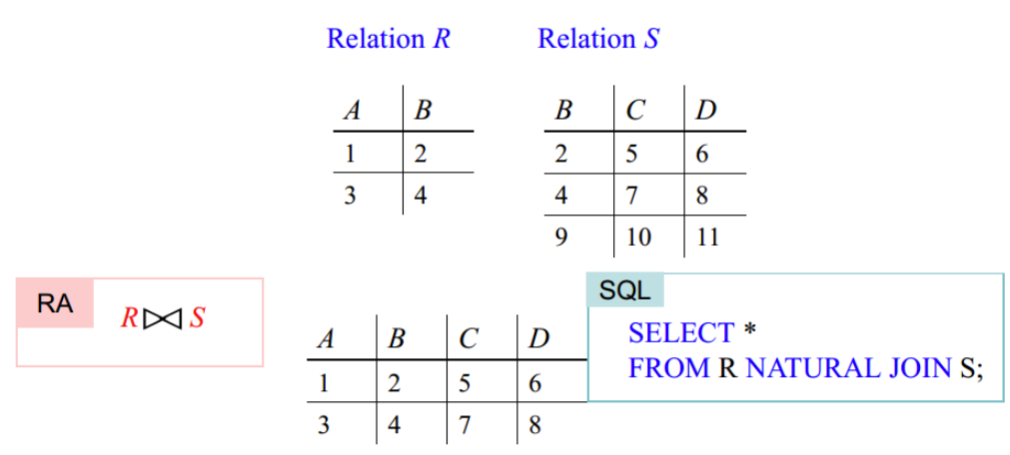
$\theta$-连接
关系 $R$ 与 $S$ 先做笛卡尔积,在从中选择满足条件 $C$ 的部分(Theta-Joins)。可表示为 $ R \bowtie_{C} S $
对应的SQL语言:
1SELECT * FROM R INNER JOIN S ON C;
重命名
将关系 $R$ 重命名为关系 $S$,$R$ 中对应的属性重命名为 $A_1, A_2, \cdots, A_n$。可表示为 $\rho_{S(A_1, A_2, \cdots, A_n)}(R)$
对应的SQL语言:
1SELECT a_1 AS A_1, a_2 AS A_2, ..., a_n AS A_n FROM R AS S;
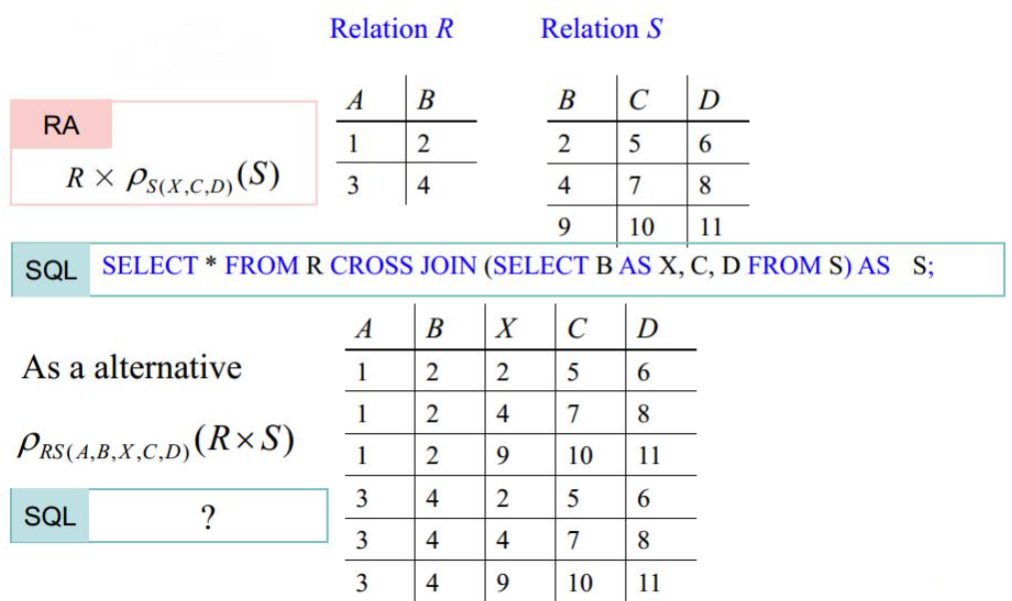
SQL语言
SQL语句分类:
| 分类 | 全称 | 说明 |
|---|---|---|
| DDL | Data Definition Language | 数据定义语言,用于定义数据库对象 |
| DML | Data Manipulation Language | 数据操作语言,用于数据库中数据的增删改 |
| DQL | Data Query Language | 数据查询语言,用于查询数据库中表的记录 |
| DCL | Data Control Language | 数据控制语言,用于创建数据库用户、控制数据库访问权限 |
SQL的数据类型
| 数字类型 | 大小 | 描述 |
|---|---|---|
TINYINT |
1 byte | 小整数集 |
SMALLINT |
2 bytes | 大整数集 |
MEDIUMINT |
3 bytes | 大整数集 |
INT |
4 bytes | 大整数集 |
BIGINT |
8 bytes | 极大整数集 |
FLOAT |
4 bytes | 单精度浮点数集 |
DOUBLE |
8 bytes | 双精度浮点数集 |
DECIMAL |
依赖精度值(总数位)和标度值(小数位) | 精确定点数 |
| 字符串类型 | 大小 | 描述 |
|---|---|---|
CHAR() |
0-255 bytes | 定长字符串 |
VARCHAR() |
0-65,535 bytes | 变长字符串 |
TINYBLOB |
0-255 bytes | 二进制数据 |
TINYTEXT |
0-255 bytes | 短文本字符串 |
BLOB |
0-65,535 bytes | 二进制长文本数据 |
TEXT |
0-65,535 bytes | 长文本数据 |
MEDIUMBLOB |
0-16,777,215 bytes | 二进制中等长度文本数据 |
MEDIUMTEXT |
0-16,777,215 bytes | 中等长度文本数据 |
LONGBLOB |
0-4,294,967,295 bytes | 二进制极大文本数据 |
LONGTEXT |
0-4,294,967,295 bytes | 极大文本数据 |
| 日期类型 | 大小 | 格式 | 描述 |
|---|---|---|---|
DATA |
3 | YYYY-MM-DD |
日期值 |
TIME |
3 | HH:MM:SS |
时间值或持续时间 |
TEAR |
1 | YYYY |
年份值 |
DATETIME |
8 | YYYY-MM-DD HH:MM:SS |
混合日期和时间值 |
TIMESTAMP |
4 | YYYY-MM-DD HH:MM:SS |
时间戳 |
空值NULL |
|
|---|---|
| 出现情况 | 值本身未知、值不适用于目标对象、用作保留值 |
| 运算法则 | 对NULL进行算术操作,结果仍为NULL 对 NULL进行逻辑操作,结果为UNKNOWN |
空值
NULL不是常量,不可将其用作操作数。
| 布尔类型 | 约定值 |
|---|---|
TRUE |
1 |
FALSE |
0 |
UNKNOWN |
1/2 |
布尔操作的法则:
AND操作符返回两者约定值较小的那个。OR操作符返回两者约定值较大的那个。- 布尔变量
v反转后为1-v。例如,若执行SQL语句
1SELECT * FROM Movies WHERE length<=120 OR length>120;若某些元组的
length值为NULL,条件的返回值则为UNKNOWN,将不会出现在结果中。
DDL
数据定义语言,用于定义数据库对象
- 查询
1/* -- 数据库操作 -- */
2-- 查询所有数据库
3SHOW DATABASES;
4
5-- 查询当前数据库
6SELECT DATABASE();
7
8-- 查询当前数据库中所有表
9SHOW TABLE;
10
11
12/* -- 表操作 -- */
13-- 查询表结构
14DESC 表名;
15
16-- 查询指定表的建表语句
17SHOW CREATE TABLE 表名;
- 创建
1/* -- 数据库操作 -- */
2-- 创建数据库
3CREATE DATABASE [IF NOT EXISTS] 数据库名 [DEFAULT CHARSET 字符集] [COLLATE 排序规则];
4
5-- 使用数据库
6USE 数据库名;
7
8
9/* -- 表操作 -- */
10-- 创建表
11CREATE TABLE 表名 (
12 字段1 字段1类型 PRIMARY KEY, [COMMENT '这是主键'],
13 字段2 字段2类型 [COMMENT '字段2注释'],
14 字段3 字段3类型 [COMMENT '字段3注释'],
15 ...
16) [COMMENT '表注释'];
17
18-- 示例
19CREATE TABLE movie (
20 name CHAR(30),
21 address VARCHAR(255),
22 cert INT PRIMARY KEY [COMMENT '主键'],
23 networth INT
24);
25
26CREATE TABLE studio (
27 name CHAR(50) PRIMARY KEY,
28 address VARCHAR(255),
29 presc INT,
30 FOREIGN KEY (presc) REFERENCES movie(cert) [COMMENT '外键']
31);
MySQL中建议使用字符集
UTF8mb4。参见:MySQL的数据类型
- 修改
1--- 添加字段
2ALTER TABLE 表名 ADD 字段名 类型(长度) [COMMENT '注释'] [约束];
3
4--- 修改数据类型
5ALTER TABLE 表名 MODIFY 字段名 新数据类型(长度);
6
7--- 修改字段名和字段类型
8ALTER TABLE 表名 CHANGE 旧字段名 新字段名 类型(长度) [COMMENT '注释'] [约束];
9
10--- 修改表名
11ALTER TABLE 表名 RENAME TO 新表名;
- 删除
1--- 删除字段
2ALTER TABLE 表名 DROP 字段名;
3
4-- 删除表
5DROP TABLE [IF EXISTS] 表名;
6
7-- 删除指定表,并重新创建该表
8TRUNCATE TABLE 表名;
9
10--- 删除数据库
11DROP DATABASE [IF EXISTS] 数据库名;
DML
数据操作语言,用于数据库中数据的增删改。
- 添加数据(Insertion)
1-- 给指定字段添加数据
2INSERT INTO 表名(字段名1, 字段名2, ...) VALUES(值1,值2,...);
3
4-- 给全部字段添加数据
5INSERT INTO 表名 VALUES(值1,值2,...);
6
7/* -- 批量添加数据 -- */
8-- 指定字段名添加
9INSERT INTO 表名(字段名1,字段名2,...) VALUES(值1,值2,...),(值1,值2,...),(...);
10
11-- 全部添加
12INSERT INTO 表名 VALUES(值1,值2,...),(值1,值2,...),(值1,值2,...);
注意:
- 插入数据时,指定的字段顺序需要与值的顺序相对应。
- 字符串和日期型数据应包含在引号中。
- 插入数据的大小应该在字段的指定范围内。
- 修改数据(Updates)
1UPDATE 表名 SET 字段名1=值1,字段名2=值2,... [WHERE 条件];
2-- 作用是修改满足条件的一行数据对应字段的值,不是修改字段名
3-- 如果没有修改条件,则会修改整张表中所有数据
- 删除数据(Deletion)
1DELETE FROM 表名 [WHERE 条件];
2-- 如果没有修改条件,则会修改整张表中所有数据
3-- DELETE语句不能删除某一个字段的值,可以使用UPDATE将该字段值设为NONE
DQL
数据查询语言,用于查询数据库中表的记录。它完整的参数可包含如下内容:
1SELECT [字段列表] FROM [表名列表] WHERE [条件列表] GROUP BY [分组字段列表]
2HAVING [分组后筛选列表] ORDER BY [排序字段列表] LIMIT [分页参数];
基本条件查询
1SELECT L FROM R WHERE C [ORDER BY 排序规则];
它与关系代数 $\pi_{L}(\sigma_{C}(R))$ 对应。
常用运算符总结:
| 运算符 | 功能 | 运算符 | 功能 |
|---|---|---|---|
| > | 大于 | IN(...) |
在in之后的列表中的值(多选一) |
| >= | 大于等于 | LIKE ' ' |
模糊匹配 |
| < | 小于 | IS NULL |
数据为空 |
| <= | 小于等于 | AND 或 && |
逻辑与 |
| = | 等于 | OR 或 || |
逻辑或 |
| <> 或 != | 不等于 | NOT 或 ! |
逻辑非 |
| BETWEEN…AND… | 在某个范围之间(含端点) |
LIKE后可接一个通配符,用于模糊匹配字段
"Star ____"将匹配字段中含有一个Star和4个字符的字符串。%"s%将匹配包含's的字符串。- SQL允许使用
ESCAPE命令来排除特定的字符,例如'x%%x%' ESCAPE 'x'将匹配以%开头和结尾的字符串。
查询结果可通过参数ORDER BY排序,默认为升序排列。可通过ORDER BY DESC指定为降序排列,ORDER BY ASC为升序排列。
多表查询
FROM后可接多个表,例如
1SELECT name FROM Movies, MovieExec WHERE title="Star Wars" AND producerC# = cert#;
其中title和producerC#位于表Movies中、cert#位于表MovieExec中,则查询结果将返回producerC#与cert#字段相同,且title为"Star Wars"的内容。
反身查询
若要在同一张表中查询元组内部元素之间的关系,则需对该表设置两个副本再进行查询。
例如,查询哪两个Star有相同的address,则输入:
1SELECT Star1.name, Star2.name
2FROM MovieStar Star1, MovieStar Star2
3WHERE Star1.address = Star2.address AND Star1.name < Star2.name
必须设置两个副本
Star1和Star2,否则条件判断将始终为TRUE。
对应的关系代数为:
$$\pi_{A_1, A_5}(\sigma_{A_2 = A_6 \ \mathrm{AND}\ A_1 < A_5}(\rho_{M(A_1, A_2, A_3, A_4)}(\mathrm{MovieStar}) \times \rho_{N(A_5, A_6, A_7, A_8)}(\mathrm{MovieStar})))$$子查询
查询也可成为其他查询的一部分,像这样嵌套在查询内部的查询称作子查询。
子查询可返回单个常量,用于WHERE语句;也可以返回一个关系;还可以在FROM语句中后接元组变量。
这里主要展示返回标量值的子查询。
标量值(Scalar):元组的一个组成部分。例如元组
Movies(title, year, length, genre, studioName, producerC#)中,若使用SQL查询:1SELECT producerC# FROM Movies WHERE title='Star Wars';返回值即为一个标量值。
示例:
1SELECT name FROM MovieExec
2WHERE cert# = (SELECT producerC# FROM Movies WHERE title='Star Wars');
分组与聚合
聚合:将关系中的某些列合并。
| 聚合操作符 | 作用 |
|---|---|
SUM |
对数值列求和 |
AVG |
对数值列求平均值 |
MIN |
数值列的最小值 |
MAX |
数值列的最大值 |
COUNT |
列中值的数量 |
分组:将元组的值分为若干组。GROUP BY后接一组分组属性,元组根据分组属性的值进行分组。
分组后筛选:HAVING后接关于组的条件。
关系数据库设计
依赖(Dependency)涉及如何构建一个良好的关系数据库模式,以及当一个模式存在缺陷时如何改进的问题,并使用“异常”来指代这些问题。
函数依赖
定义
如果两个元组在属性 $A_1, A_2, \cdots, A_n$ 上一致(即它们对应属性的分量值都相等),那么它们必定在其他属性上 $B_1, B_2, \cdots, B_m$ 上也一致。记作
$$A_1 A_2 \cdots A_n \rightarrow B_1 B_2 \cdots B_m$$即 $B_1, B_2, \cdots, B_m$ 函数依赖 $A_1, A_2, \cdots, A_n$,或称 $A_1, A_2, \cdots, A_n$ 函数决定 $B_1, B_2, \cdots, B_m$。
若 $A_1 A_2 \cdots A_n \rightarrow B_1 B_2 \cdots B_m$ 成立,则以下各式均成立:
$$\begin{array}{c} A_1 A_2 \cdots A_n \rightarrow B_1 \\ A_1 A_2 \cdots A_n \rightarrow B_2 \\ \cdots \\ A_1 A_2 \cdots A_n \rightarrow B_m \end{array}$$
如果关系 $R$ 的每个实例都满足一个确定的函数依赖 $f$,那么称 $R$ 满足 函数依赖 $f$,即在 $R$ 上声明了一个约束。
关系的键
若属性集 $\{A_1, A_2, \cdots, A_n\}$ 满足:
- 它们决定关系的所有其他属性,即关系 $R$ 不可能存在两个不同的元组具备相同的 $A_1, A_2, \cdots, A_n$ 值。
- 在 $\{A_1, A_2, \cdots, A_n\}$ 的所有真子集均不能决定关系 $R$ 的所有其他属性,即键必须是最小的。
则称 $\{A_1, A_2, \cdots, A_n\}$ 是关系 $R$ 的键。
可以将关系 $R$ 中的键类比为 $n$ 维线性空间的一个 $n$ 元向量组 $[\bm{e}_1, \bm{e}_2, \cdots, \bm{e}_n]$,它可以表示该空间内的所有向量。
有时,一个关系可能会有多个可行的键,这时需指定其中一个为主键(Primary key)。
一个包含键的属性集就称为超建。
容易得出,每个键都是该关系的超键($A \subseteq A$)
函数依赖的规则
函数依赖的规则给出了推导函数依赖的一般方法。
分解/结合规则
函数依赖 $A_1 A_2 \cdots A_n \rightarrow B_1 B_2 \cdots B_m$ 等价于下列函数依赖的集合:
$$\begin{array}{c} A_1 A_2 \cdots A_n \rightarrow B_1 \\ A_1 A_2 \cdots A_n \rightarrow B_2 \\ \cdots \\ A_1 A_2 \cdots A_n \rightarrow B_m \end{array}$$从左到右称作函数依赖的分解规则,从右到左称作函数依赖的结合规则。
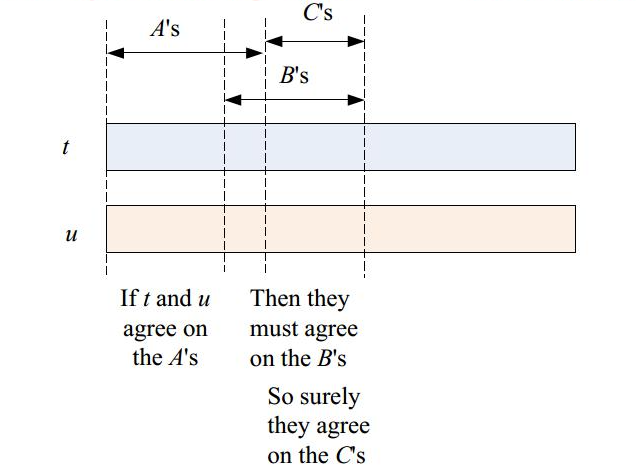
平凡函数依赖
对于函数依赖 $A_1 A_2 \cdots A_n \rightarrow B_1 B_2 \cdots B_m$,若满足
$$\{B_1 B_2 \cdots B_m\} \subseteq \{A_1 A_2 \cdots A_n\}$$则称其为 平凡函数依赖。
若 $A_1 A_2 \cdots A_n \rightarrow B_1 B_2 \cdots B_m$,且 $\{B_1, B_2, \cdots, B_m\} - \{A_1, A_2, \cdots, A_n\} = \{C_1, C_2, \cdots, C_k\}$,则有
$$A_1 A_2 \cdots A_n \rightarrow C_1 C_2 \cdots C_k$$这称为平凡依赖规则。如图所示:
平凡依赖规则
属性的闭包
设 $\{A_1, A_2, \cdots, A_n\}$ 是属性集合,$S$ 是函数依赖的集合,则 $S$ 下属性集合 $\{A_1, A_2, \cdots, A_n\}$ 的闭包定义为:满足 $S$ 中所有函数依赖关系的属性集合 $B$,记作 $\{A_1, A_2, \cdots, A_n\}^+$
计算属性闭包的方法:
- 设 $X$ 是属性集合 $\{A_1, A_2, \cdots, A_n\}$ 的闭包,首先令 $X = \{A_1, A_2, \cdots, A_n\}$。
- 反复寻找函数依赖 $B_1 B_2 \cdots B_n \rightarrow C$ ,使得 $B_1, B_2, \cdots, B_n$ 在 $X$ 中且 $C$ 不再 $X$ 中。然后把 $C$ 加入 $X$。
- 重复这个过程,直至无法再添加新的元素到 $X$ 中,计算结束,此时 $\{A_1, A_2, \cdots, A_n\}^+ = X$。
传递规则
若关系 $R$ 满足 $A_1 A_2 \cdots A_n \rightarrow B_1 B_2 \cdots B_m$ 和 $B_1 B_2 \cdots B_m \rightarrow C_1 C_2 \cdots C_k$,则有
$$A_1 A_2 \cdots A_n \rightarrow C_1 C_2 \cdots C_k$$Armstrong公理
公理 定义 自反律 如果 $\{B_1 B_2 \cdots B_m\} \subseteq \{A_1 A_2 \cdots A_n\}$,那么 $A_1 A_2 \cdots A_n \rightarrow B_1 B_2 \cdots B_m$ 增广律 如果 $A_1 A_2 \cdots A_n \rightarrow B_1 B_2 \cdots B_m$,那么 $A_1 A_2 \cdots A_n C_1 C_2 \cdots C_k \rightarrow B_1 B_2 \cdots B_m C_1 C_2 \cdots C_k$ 传递律 如果 $A_1 A_2 \cdots A_n \rightarrow B_1 B_2 \cdots B_m$ 且 $B_1 B_2 \cdots B_m \rightarrow C_1 C_2 \cdots C_k$,那么 $A_1 A_2 \cdots A_n \rightarrow C_1 C_2 \cdots C_k$
函数依赖的投影
记 $R_1 = \pi_{L} (R)$,函数依赖集合 $S$ 的投影是满足下列条件的函数依赖的集合:
- 从 $S$ 推断而来
- 只包含 $R_1$ 的属性
模式设计
关系的分解
将关系进行分解(decompose)可用来消除异常。
给定关系 $R(A_1, A_2, \cdots, A_n)$,把它分解为关系 $S(B_1, B_2, \cdots, B_m)$ 和 $T(C_1, C_2, \cdots, C_k)$,需满足:
- $\{A_1, A_2, \cdots, A_n\} = \{B_1, B_2, \cdots, B_m\} \cup \{C_1, C_2, \cdots C_k\}$
- $S = \pi_{B_1, B_2, \cdots, B_m} (R)$
- $T = \pi_{C_1, C_2, \cdots, C_k} (R)$
BC范式
分解的目的就是将一个关系用多个不存在异常的关系替换,即在一个简单的条件下保证异常不存在,这个条件就称作BC范式(BCNF)。
定义:当且仅当如果关系 $R$ 中非平凡函数依赖 $A_1 A_2 \cdots A_n \rightarrow B_1 B_2 \cdots B_m$ 成立,则 $\{A_1, A_2, \cdots, A_n\}$ 是关系 $R$ 的超键。此时称关系 $R$ 为BC范式。
换言之,就是每个非平凡函数依赖的左侧必须包含该关系的键。
分解为BC范式
目标:将任何一个关系模式分解为带有以下性质的、具有多个属性的子集:
- 以这些子集为模式的关系都属于BCNF。
- 原始关系中的数据都被正确地反映在分解后的关系上,简单而言就是原始关系应能从分解后的几个关系实例中重构。
对于任意关系 $R$ 和函数依赖集合 $S$,有BCNF分解算法:
- 检验 $R$ 是否为BCNF,若是,直接返回 $R$。
- 如果存在违反BCNF的函数依赖,假设为 $X \rightarrow Y$。计算 $X$ 的闭包 $X^+$。选择 $R_1 = X^+$ 作为一个关系模式,并使另一个关系模式 $R_2$ 包含属性 $X$ 以及不在 $X^+$ 的属性。
- 计算 $R_1$ 和 $R_2$ 的函数依赖集合,记为 $S_1$ 和 $S_2$,并递归地分解 $R_1$ 和 $R_2$,返回最终分解的集合。
分解的优劣
一个分解应当具有3个性质:
| 性质 | 特点 |
|---|---|
| 消除异常 | |
| 信息可恢复 | 能够从分解后的各个元组中恢复原始关系。 |
| 依赖的保持 | 如果函数依赖的投影在分解后的关系上成立,能确保对分解后的关系用连接重构获取原始关系仍然满足原来的函数依赖 |
事实上,没有一种分解能同时具备以上3个性质。
从分解中恢复信息
若可以通过分解后的各个关系重构原关系 $R$,则称该分解含有无损连接。
设关系 $R(X,Y,Z)$,且具备函数依赖 $X \rightarrow Y$,则可以依据BCNF分解算法将关系分解为 $R_1(X,Y)$ 和 $R_2(Y,Z)$,且
$$R = \pi_{X \cup Y}(R) \bowtie \pi_{Y \cup Z}(R)$$即该分解包含无损连接。
无损连接的检验
设关系 $R$ 被分解为若干关系,它们的属性集分别为 $S_1, S_2, \cdots, S_k$,在 $R$ 上成立的函数依赖集合为 $F$。则 $\pi_{S_1}(R) \bowtie \pi_{S_2}(R) \bowtie \cdots \bowtie \pi_{S_k}(R) = R$ 成立当且仅当连接结果中的每个元组都属于 $R$。这称为无损连接的chase检验。
依赖的保持
在某些情况下,把一个关系分解为一系列BCNF关系时,无法同时拥有无损连接和依赖保持两种性质。
第三范式
定义:如果一个关系 $R$ 满足只要 $A_1 A_2 \cdots A_n \rightarrow B_1 B_2 \cdots B_m$ 是非平凡函数依赖,那么或者 $\{A_1, A_2 ,\cdots, A_n\}$ 是超键,或者每个属于 $B_1, B_2, \cdots, B_n$ 但不属于 $A$ 的属性都是某个键的成员。
如果一个属性是某个键的成员,则常被成为“主属性”。因此,3NF的条件等价于:对于每个非平凡FD,或者其左边是超键,或者其右边仅由主属性构成。
多值依赖
MySQL
MySQL是目前流行的数据库管理系统,使用SQL语法操作和管理。
准备工作
1# 安装MYSQL
2sudo apt-get install mysql-server
3
4# 启动MySQL服务
5sudo service mysql start
6
7# 登录MySQL
8mysql -u '用户名' -p '密码'
配置MySQL
首先进入MySQL界面,然后操作:
设置用户密码
1ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY '你的新密码';
2FLUSH PRIVILEGES;
3EXIT;
退出后以新的密码即可登录MySQL。
允许远程访问
在Shell中输入:
1sudo vim /etc/mysql/mysql.conf.d/mysqld.cnf
找到bind-address,将其修改为0.0.0.0或注释掉该行。
保存后重启服务:
1sudo service mysql restart
创建新用户
1CREATE USER '新用户名'@'%' IDENTIFIED BY '新密码';
2GRANT ALL PRIVILEGES ON *.* TO '新用户名'@'%' WITH GRANT OPTION;
3FLUSH PRIVILEGES;
退出后以新的用户名和密码即可登录MySQL。
通用语法
- 单行或多行书写,以分号结尾。
- 可以使用空格/缩进。
- SQL语句不区分大小写,关键字建议大写。
- 单行注释:
--注释内容或# 注释内容;多行注释:/* 注释内容 */。 - 其他参照SQL语言 。
openGauss
数据库管理可视化
面对单调的SQL代码是非常无聊的,因此通过软件可视化管理数据库是不错的选择。
| 软件 | 介绍 | 版本 |
|---|---|---|
| Navicat | Navicat是一款综合性的数据库管理软件,允许通过一个界面连接和管理多个数据库(其实这个功能大多数类似软件都有)。 | Navicat提供多个版本,其中只有Navicat Premium Lite可免费使用(貌似还要注册一个账号)。 |
| DBeaver | 功能与Navicat类似 | 它提供免费的社区版下载,而且不用注册账号,就像JetBrain全家桶 |
| MySQL Workbench | MySQL的官方提供的可视化管理工具 | 免费,但是没有中文支持。 |